Video Categories
Diagnosing Temporal Fidelity of Video MLLMs on Momentary Visual Events
* Equal contribution
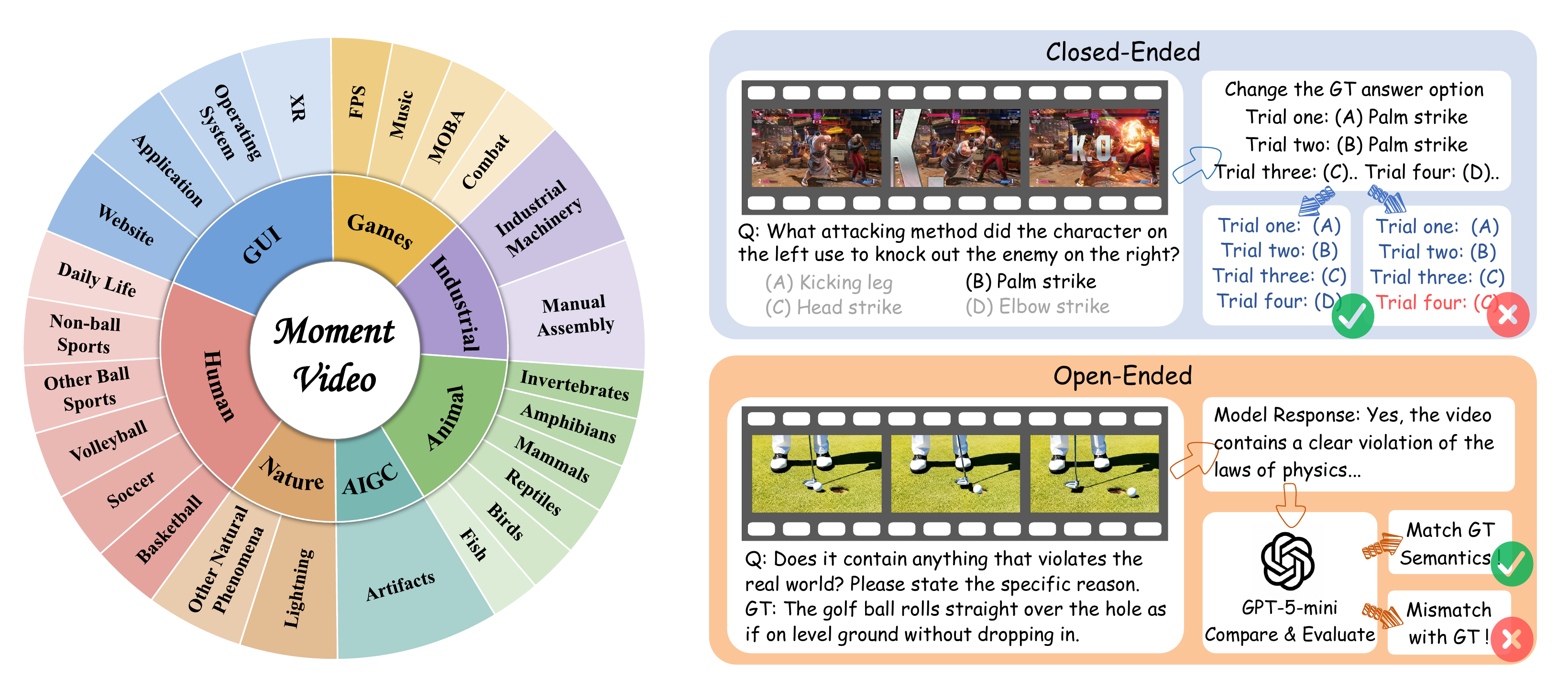
Moment-Video is a benchmark for diagnosing the temporal fidelity of video multimodal large language models (MLLMs) on momentary visual events: localized actions or state transitions that may last only a few frames, yet determine the correct answer.
Unlike benchmarks centered on persistent objects, global scene context, or long-form semantic aggregation, Moment-Video asks whether models can notice, count, describe, and reason over brief answer-critical evidence. The benchmark contains 1,000 human-verified video-QA pairs across 7 domains and 25 fine-grained subcategories, covering both real-world and virtual scenarios.
Whether a brief event or state transition happens in the video.
How many transient actions, object changes, or repeated events occur.
How a momentary event unfolds, including direction, trajectory, target, interaction, or state change.
How the pre-event state, momentary event, and post-event state imply the final answer.

We evaluate 33 proprietary and open-source video MLLMs. Seed-2.0-Pro/Lite/Mini and MIMO-v2.5 use their default frame-sampling settings. Other models are evaluated with a 64-frame cap (50-frame cap for GPT-5.4). Switch between 1 FPS and 8 FPS results below.
@misc{liu2026momentvideodiagnosingtemporalfidelity,
title={Moment-Video: Diagnosing Temporal Fidelity of Video MLLMs on Momentary Visual Events},
author={Xiaolin Liu and Yilun Zhu and Xiangyu Zhao and Xuehui Wang and Yan Li and Xin Li and Haoyu Cao and Xing Sun and Shaofeng Zhang and Xu Yang and Zhihang Zhong and Xue Yang},
year={2026},
eprint={2606.02522},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2606.02522},
}